
Part 3 in our Follow-Along Series on Building a SQL Parser with TypeScript
If you haven’t been following along, our CTO Nathan Northcutt published an in-depth series on how he built a fully functional SQL Parser with TypeScript. Without any external dependencies, the self-contained library needs to:
- Express database schemas through both types and builders that provide concrete implementations
- Build and verify a SQL query against a schema to ensure valid, compile time queries.
- Interpret raw SQL strings as queries that can be validated against a schema
- Extend the parsing to provide extensions for SQL engine variants
- Identify changes in schemas and provide migrations between versions
If you haven’t already, check out part 1: Building a TypeScript SQL Parser and part 2: Defining Schemas for Parsing on our blog.
For more, follow along in Nathan’s series of Medium articles and the GitHub repository.
How query strings become AST objects
Parsing SQL queries is a fundamental aspect of database management, and it’s crucial for optimizing database operations and ensuring efficient data retrieval. While SQL might seem straightforward at first glance, parsing SQL queries—especially when they involve multiple tables, conditions, and nested queries—requires a deeper understanding. In this episode, we’ll work on getting the compiler to treat a raw string as a fully formed type, while also parsing out the actual AST at the same time.
Later articles continue to expand the AST and work on extensions for other “non-standard” syntax options. For now, we will focus on how to allow a simple select statement with columns and aliasing from a single table.
How Query Strings Become AST Objects
Query Builders for manipulating the AST types and generating the actual tree nodes
When dealing with complex SQL queries, we sometimes need more than just basic string parsing. There are scenarios where writing compliant and efficient queries directly in SQL can be challenging, and that’s where tools to create Abstract Syntax Trees (AST) come in handy. Just like we use schema builders to structure our databases, we can build queries using a similar approach. This allows us to focus on structuring our queries correctly while letting the system handle the intricacies of SQL syntax.
To manage the complexity of queries, especially when they involve temporary tables or multiple joins, we introduce a QueryContext. This helps us keep track of all elements within a query, ensuring that each part is correctly referenced and validated. We use TypeScript’s advanced type features, such as template literal types, to manage and constrain these references, which helps us avoid issues like union type explosions that can overwhelm the compiler.
Finally, when selecting columns from multiple tables, it’s crucial to maintain clarity and avoid ambiguity. We use utility types to ensure that only valid columns from the relevant tables are selected, which minimizes errors and keeps the query logic clean. By breaking down these tasks into manageable components, we can leverage TypeScript to create robust, type-safe SQL queries that are both efficient and easy to manage.
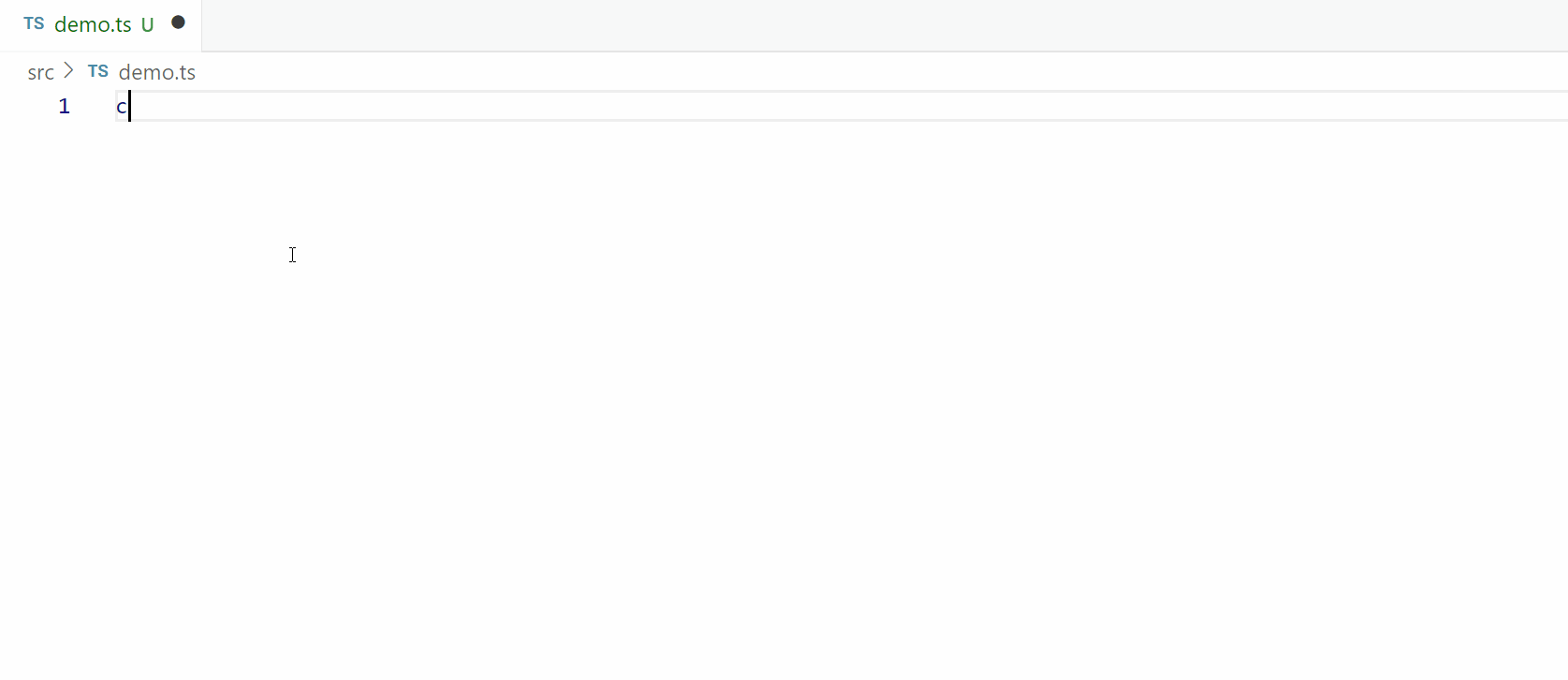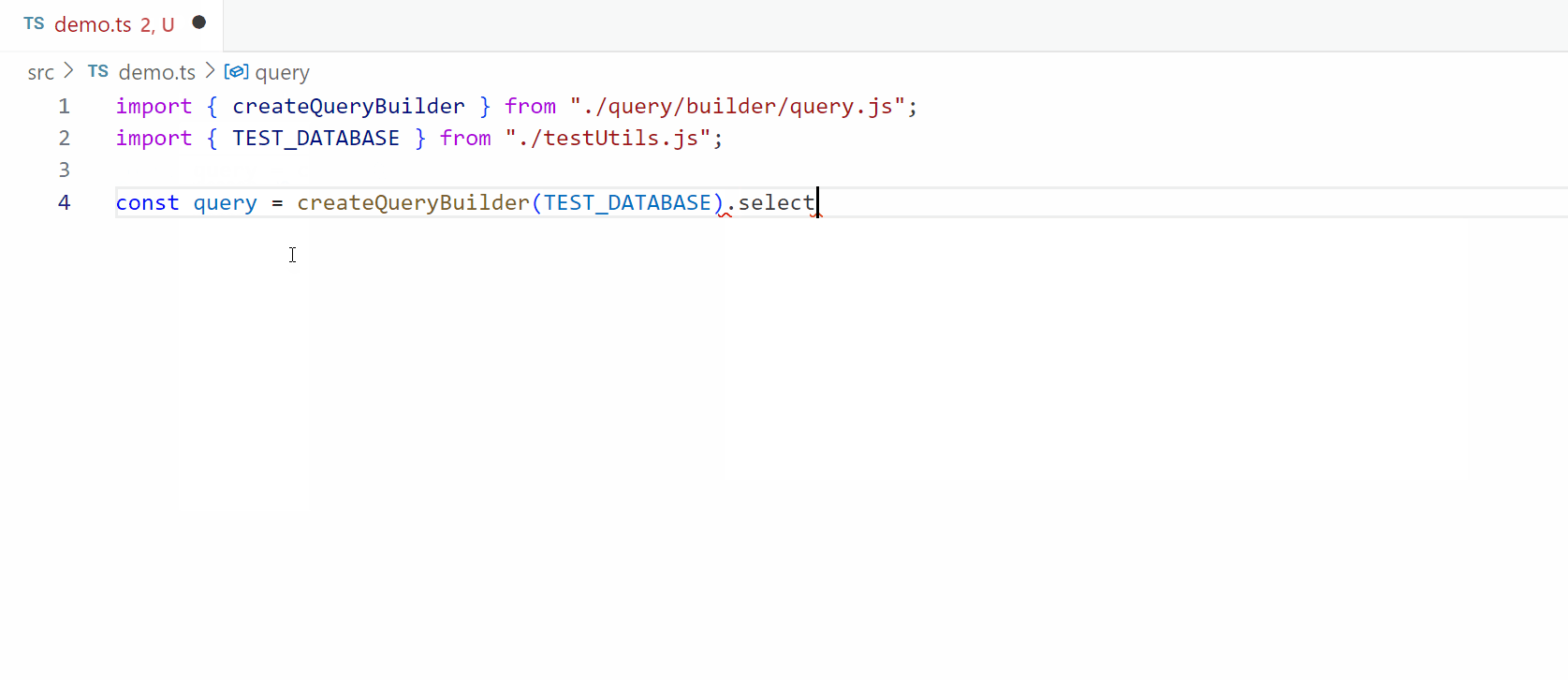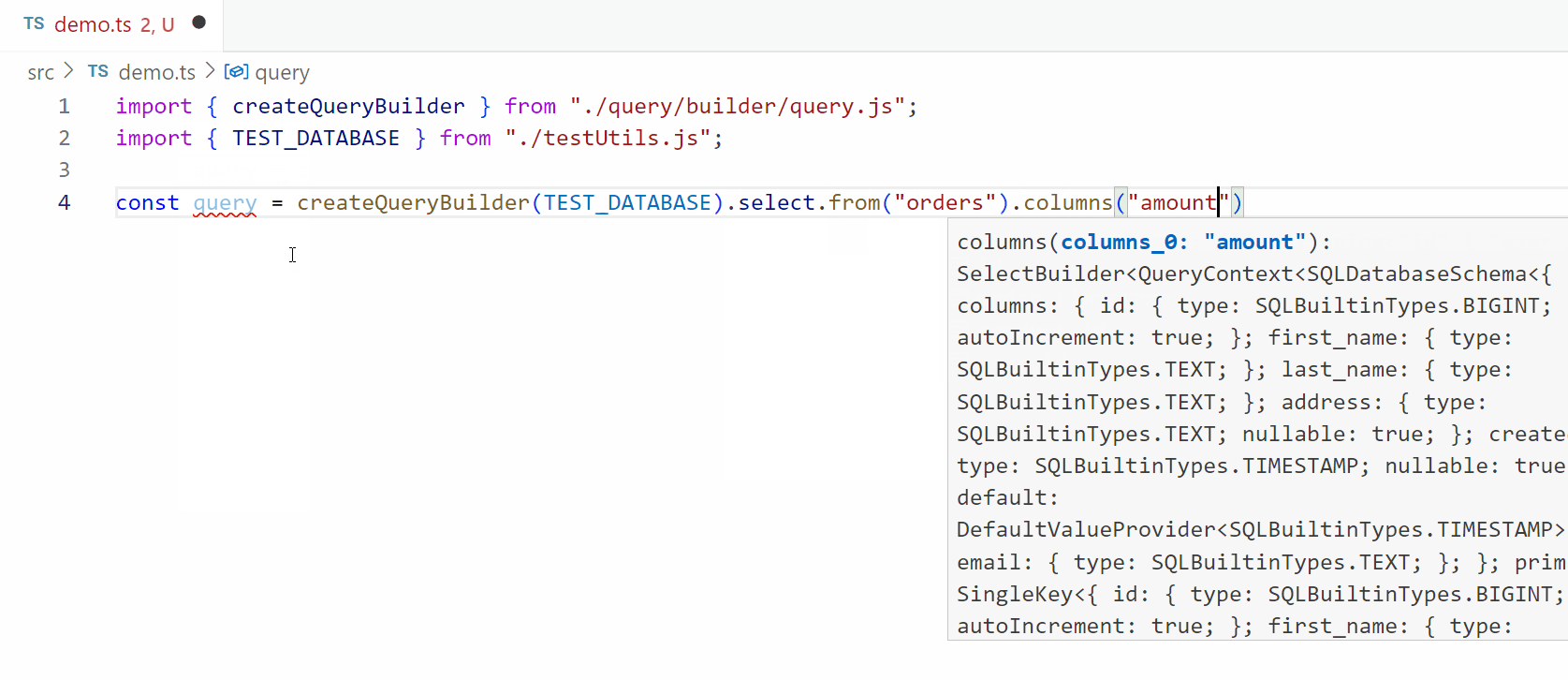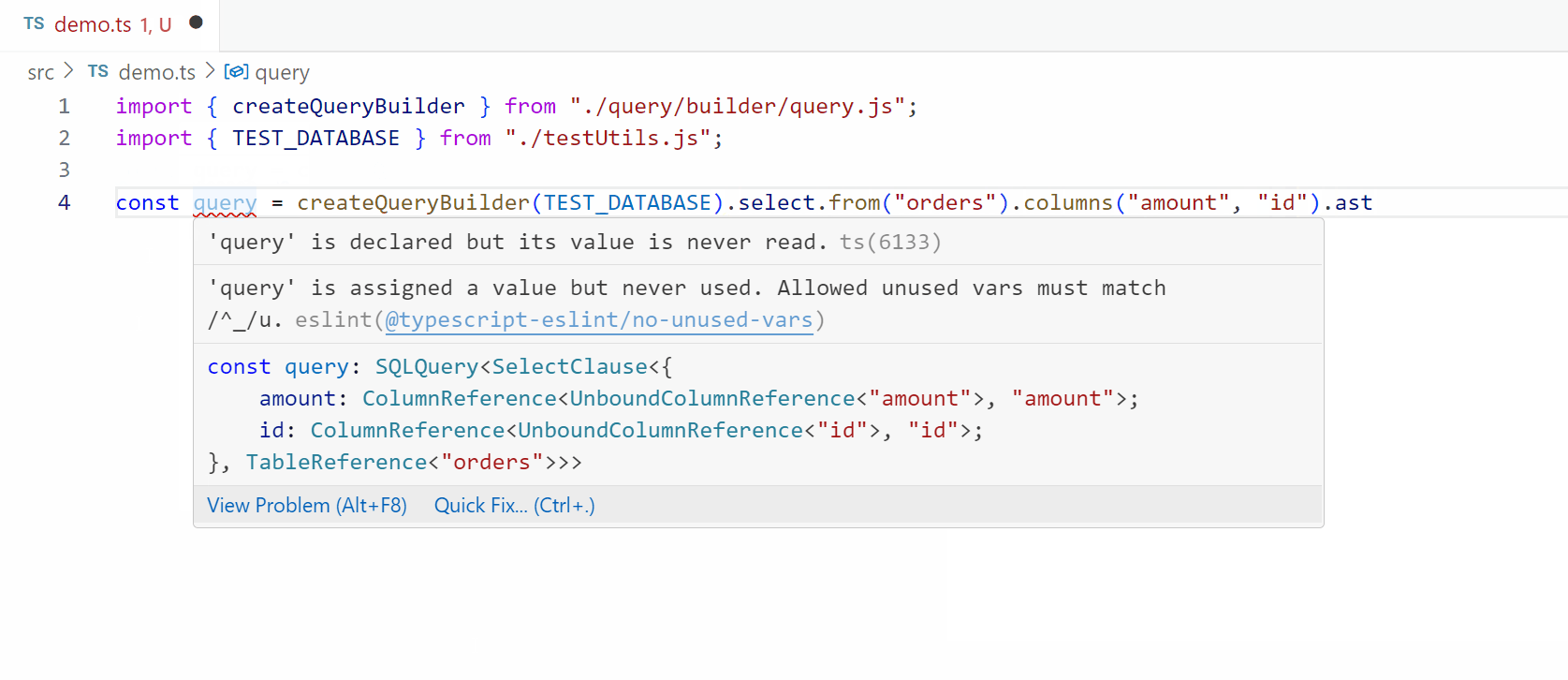
Parsing a string into an AST using “normal” functions
Next, we use builders to parse a SQL query from a string, by parsing a SelectClause from a string, which is segmented into key components. The process involves normalizing the input, ensuring that keywords are uppercase, as TypeScript’s type system is case-sensitive. This step is crucial because while databases often ignore case sensitivity, our type inference relies on consistent casing to function correctly.
Once the string is normalized, we split it into tokens and begin parsing, focusing on identifying terminal keywords like SELECT. We process these tokens until we reach a keyword that signifies the end of a section. One challenge here is handling subqueries, where keywords like WHERE might appear within nested queries. To manage this, we count open and closed parentheses to determine whether we’re within a subquery or the main query, ensuring accurate parsing.
Finally, we reconstruct the query by joining tokens and splitting column specifiers, checking for aliasing with patterns like X AS Y or T.X AS Y. This allows us to shape the Abstract Syntax Tree (AST) correctly. While the process is straightforward, it sets the stage for more complex parsing tasks we’ll tackle later, using TypeScript to handle the intricacies of SQL query parsing efficiently.
Validating an AST against a schema to ensure the types are correct
Now that we’ve built the ability to create a query AST with our builders and parse one through functions, the final piece is ensuring these queries are valid against our database schema. Simply having a syntactically correct SQL query doesn’t guarantee it will run, especially if the referenced tables or columns don’t exist. To address this, we focus on type-based validation, using TypeScript’s type system to catch errors at compile time.
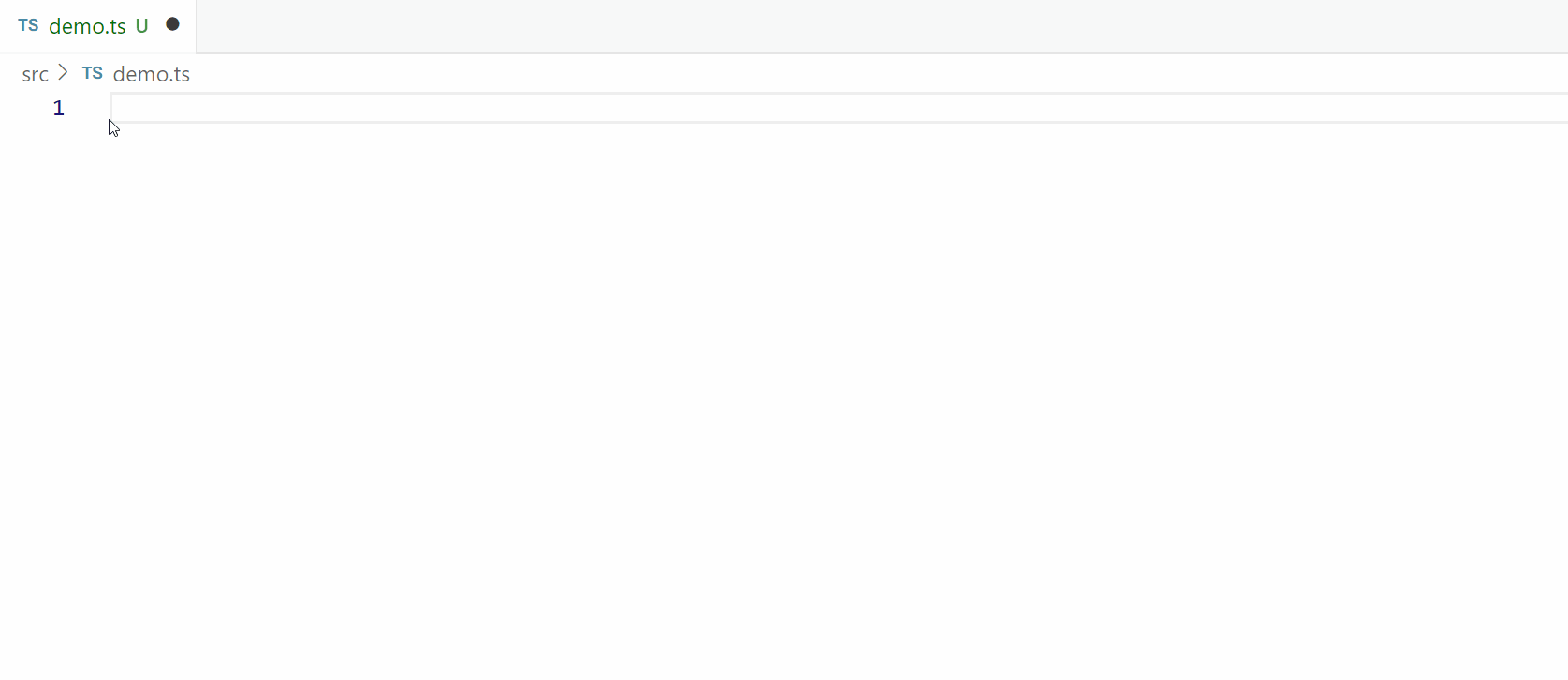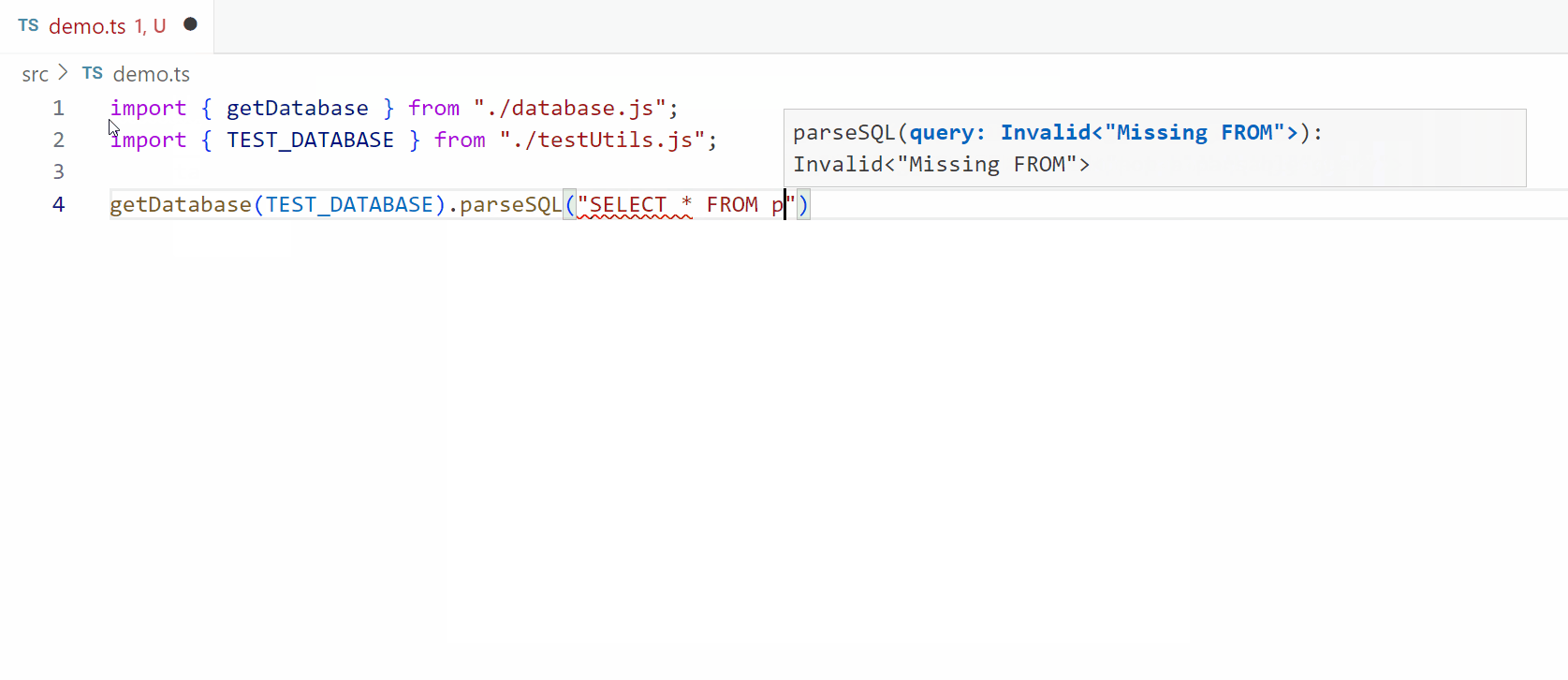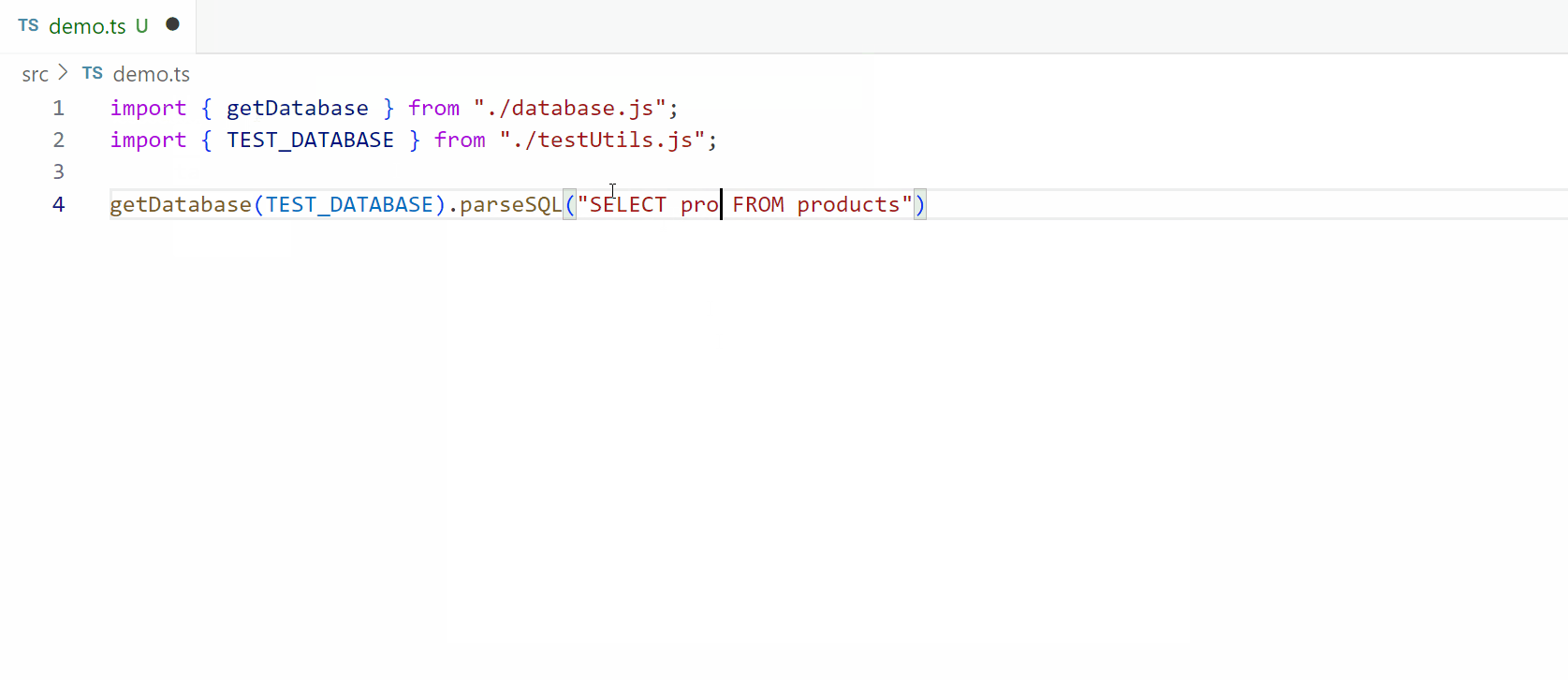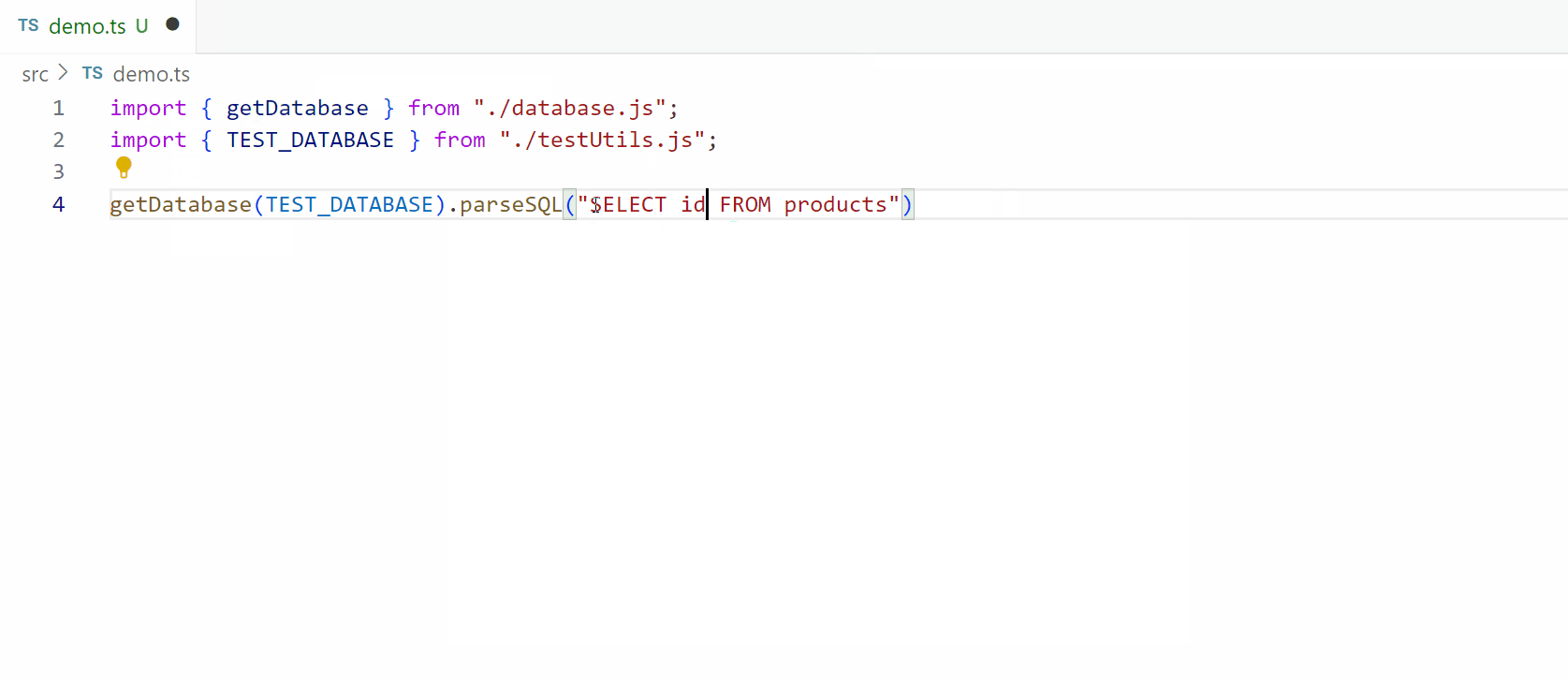
We primarily rely on the Invalid type to provide feedback during validation. This process involves a series of conditional types that verify if a query’s components, like table references and columns, are correctly defined within the database schema. If a validation check fails, it returns an Invalid type, triggering TypeScript compilation errors. This approach allows us to catch issues such as missing tables or incorrect columns before they become runtime problems.
One challenge we encounter is ensuring the proper order of elements in SQL statements, especially as we prepare for handling more complex features like ORDER BY clauses. While order isn’t critical for our current validations, it’s something we’ll need to address as we expand our capabilities. For now, our type-based validation effectively ensures that the basic structure of SQL queries aligns with the database schema, setting the stage for more advanced query validation in the future.
Interpreting raw strings as a SQL AST
We have now covered the process of parsing strings to build an AST in code. The general approach involved normalizing the string to maintain consistency, tokenizing it into manageable components, reading through these tokens to identify key structural markers, and recursively processing the tokens to build the AST. We also explored how to implement these steps using TypeScript’s type system, including recursive calls, template string types, and type inference to verify the structural integrity of the parsed SQL.
One challenge we encountered was counting parentheses to correctly handle subqueries within the parsing process. TypeScript’s type system doesn’t support counting in a conventional sense, so we had to devise a workaround. By leveraging TypeScript’s array handling, we can simulate counting by incrementing or decrementing based on the presence of opening and closing parentheses. This approach allows us to accurately track the depth of nested queries, ensuring that our parser processes only the relevant sections of the SQL string.
This counting method is essential as it forms the backbone of our parsing logic, allowing us to string together the concepts we’ve developed so far. With this technique, we can manage the complexities of subqueries and proceed with building a robust SQL parser that operates entirely within TypeScript’s type system, ensuring both correctness and compile-time validation.
Putting it all together
Now that we have all the necessary tools, it’s time to bring everything together to build our simple SELECT parser. Before diving in, there’s an important utility we need to understand that’s responsible for splitting strings into chunks while being aware of parentheses. This utility uses string template typing to identify patterns and count matching parentheses, ensuring safe splits. Although there are edge cases with invalid groupings, we assume the queries provided are generally well-formed, reducing the need for extensive error handling.
To prepare the string for parsing, we first normalize it by manually handling specific characters—like removing unnecessary whitespace or identifying key identifiers such as parentheses and quotes. This normalization process ensures that the query has a predictable and standardized shape, making the subsequent parsing steps more straightforward. Once normalized, we can use specific utility types to parse the query, starting with the ParseSQL type, which focuses on SELECT statements.
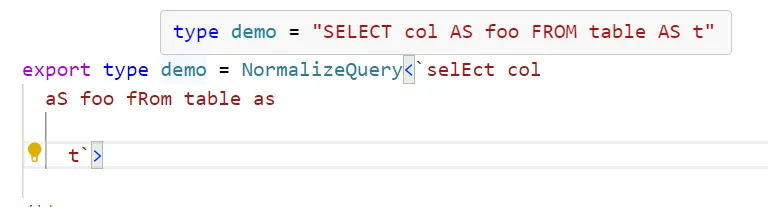
Given our focus on SELECT syntax, the parsing logic remains relatively simple: we extract columns from the query and validate them against our known types. The ParseSelect type handles the core parsing, while CheckSQL looks for any invalid types. Additional utilities ensure that column syntax is correct, using familiar loops and splitting methods to generate a properly structured array of references, which are then projected into an object with the appropriate SelectedColumns type signature. This approach keeps our parsing both efficient and robust, providing clear error messages when issues arise.
Next Steps
At last, we have the building blocks for expanding our parser to quite a few use cases. As we move into the next articles, we’ll be taking a look at where we have gaps in our original outlined goals that were outlined and work on filling in a great many statement types and strange syntax situations that could come up.
Check out the full article to go in depth with code samples:
Or go straight for the repository:
