
Part 2 in our Follow-Along Series - Defining Schemas
This is Part 2 of a series on building a type safe, compile time SQL parser, all in a self contained library that does not have any external dependencies.
Check out Part 1 where we introduced the problem.
Follow along in Nathan’s series of full articles and the GitHub repository.
Validating Queries Against a Schema
Since one of our goals for this project is to have a fully functioning parser and validator for our queries, we need something to validate against. Today we’ll be working on the schema building to produce something like the following:
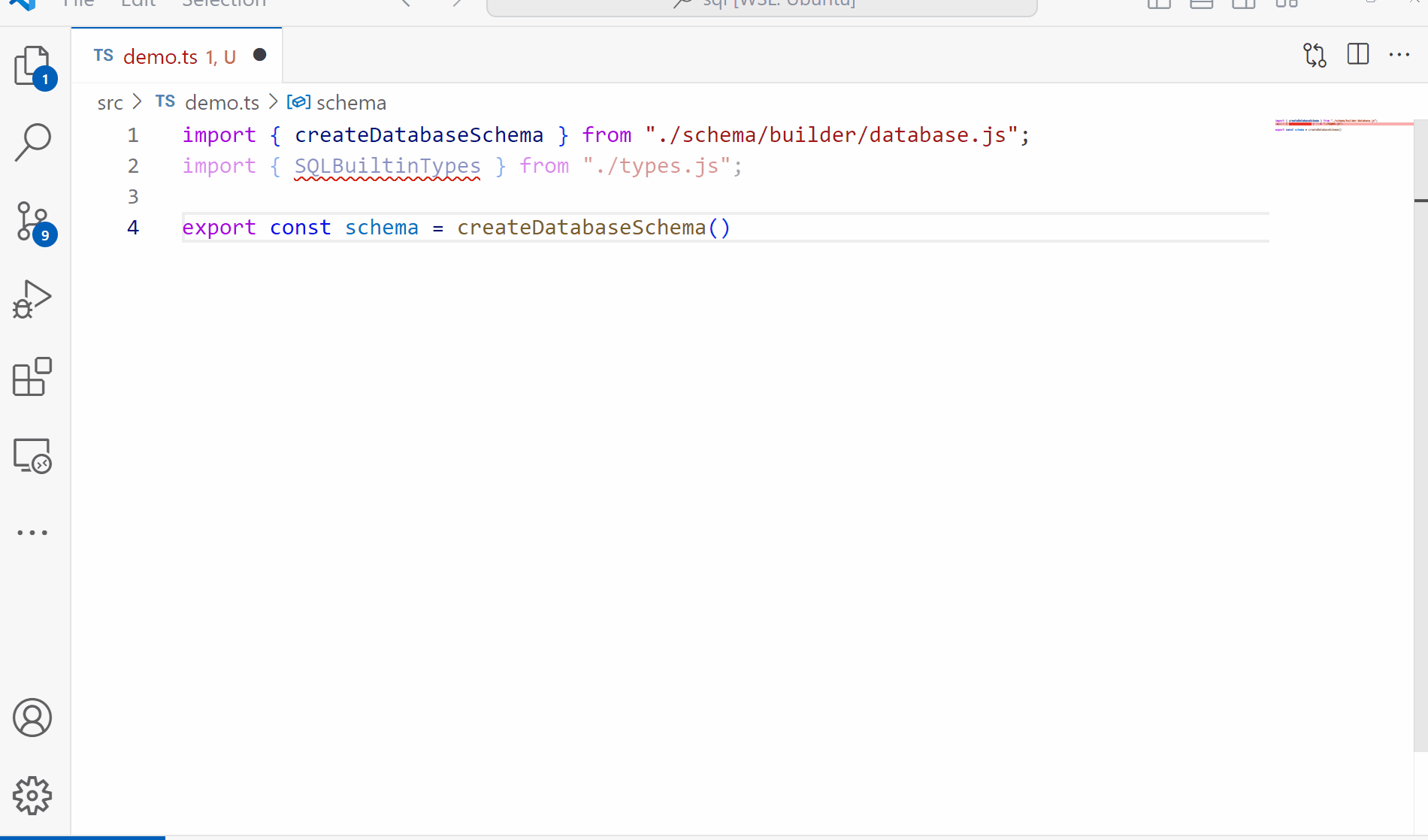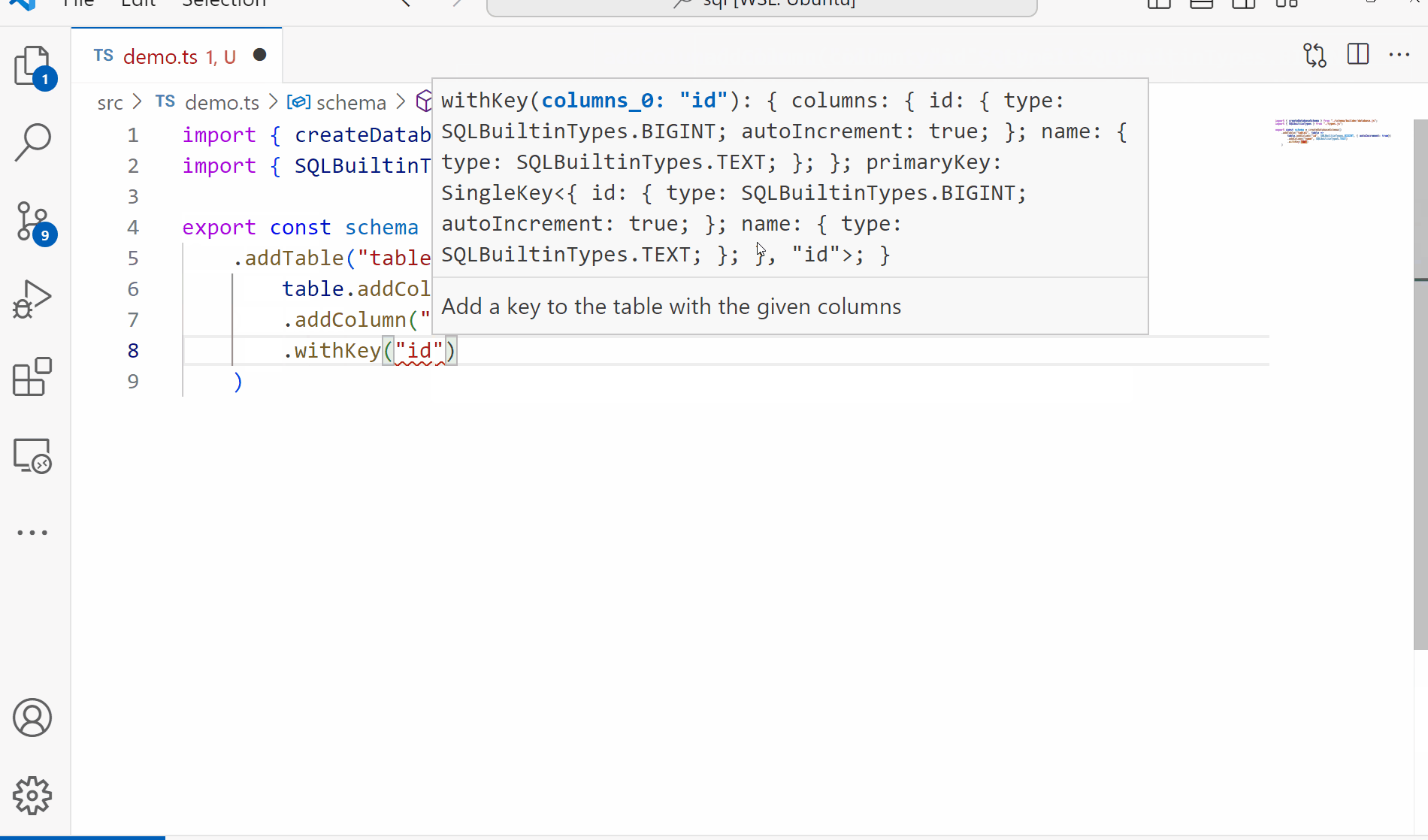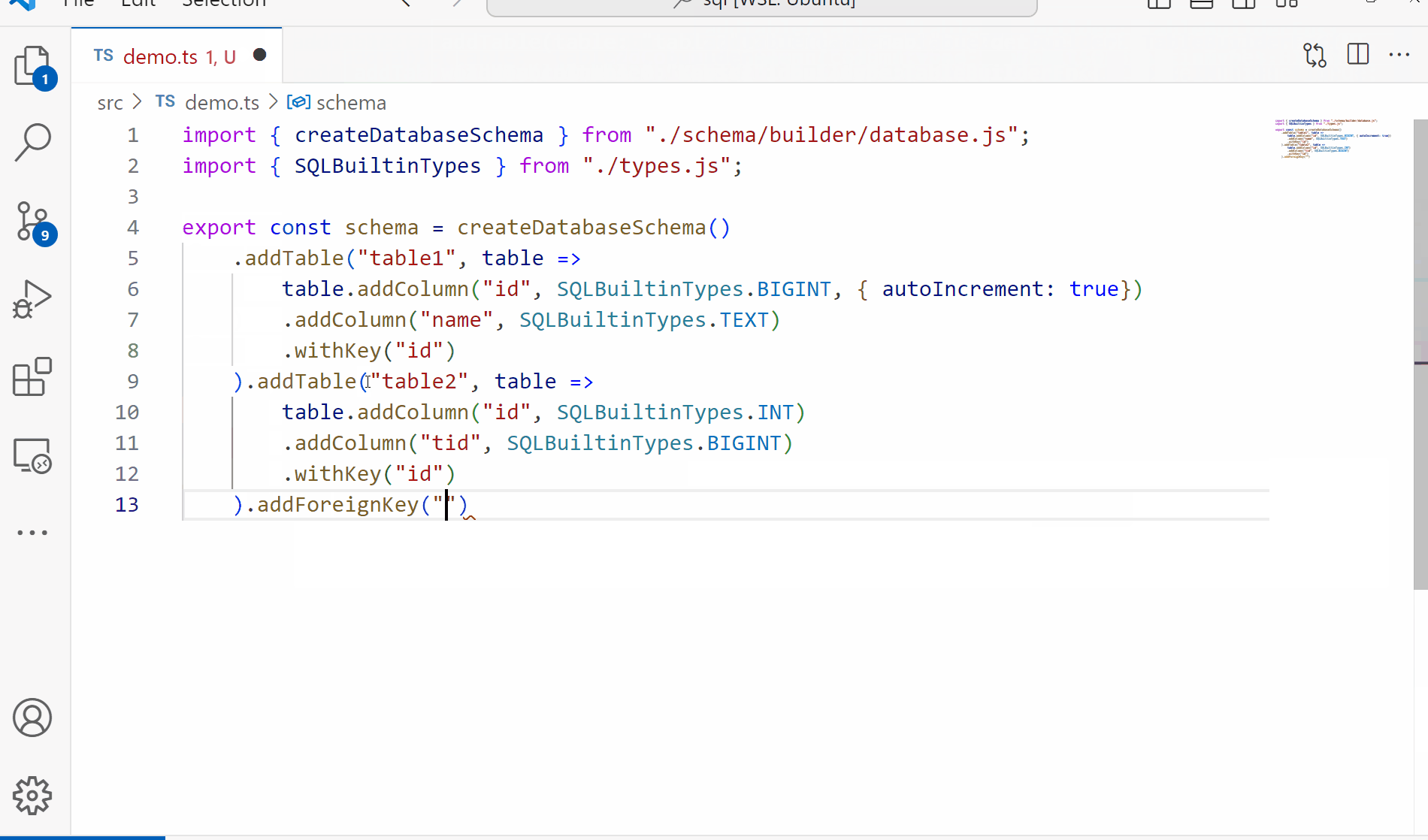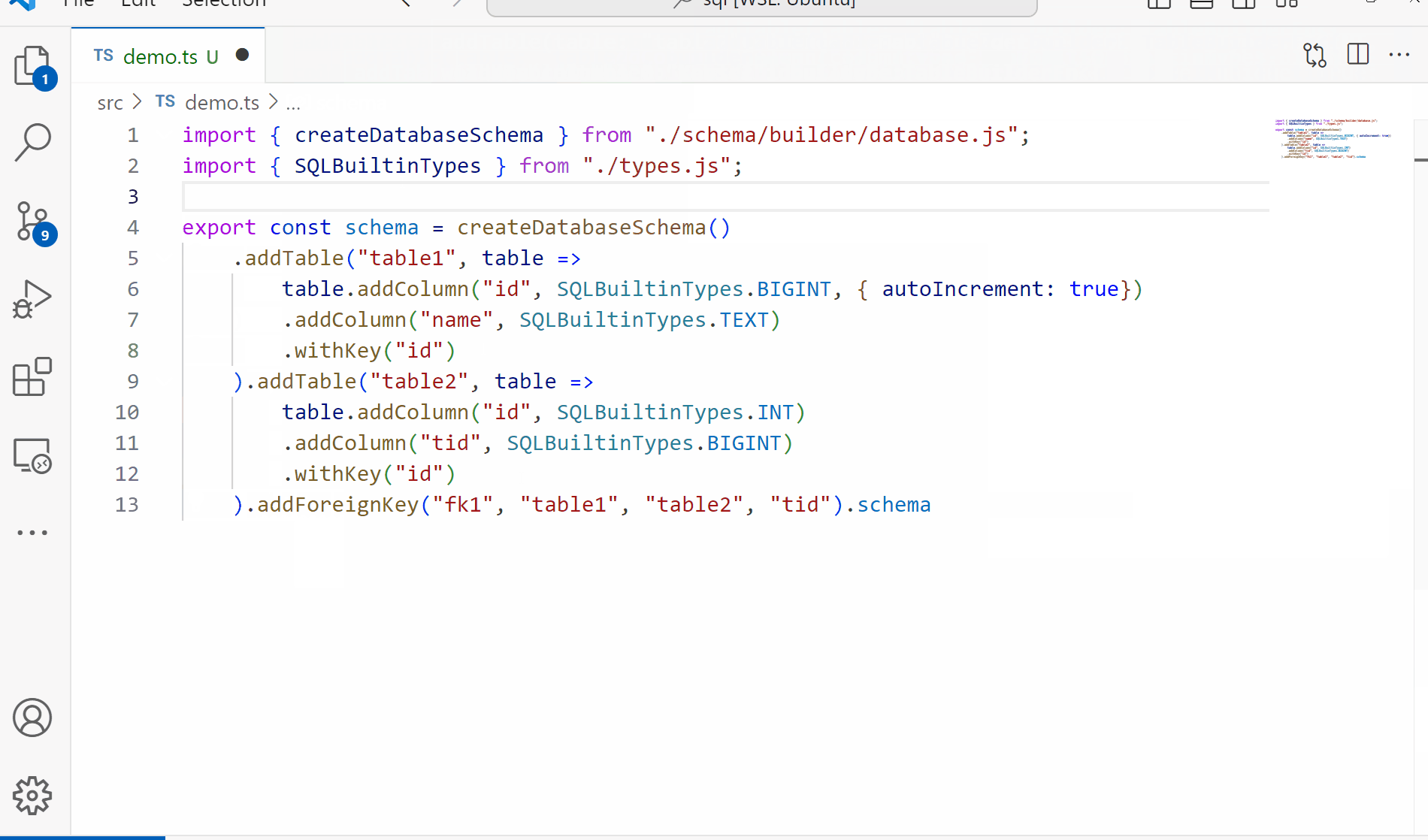
Key Concepts
Database Schemas
Different DBMS providers (MySQL, Postgres, SQL Server, Oracle) have distinct ways of handling schemas and related features. This can include differences in storage options, indexing methods, and relationship definitions. Commands and configurations that are valid in one system might not be applicable or might behave differently in the next. This variability can lead to challenges when issuing commands across different systems.
To handle these differences, we are abstracting the main structures of SQL schemas, similar to how query Abstract Syntax Trees (AST) are used. This abstraction focuses on common foundational elements such as tables and primary/foreign keys, which are fundamental across most DBMS.
Despite the differences in DBMS implementations, there is a common need to understand the general structure of a table. This includes the columns available and some options that are important for query parsing. Concentrating on these commonalities makes it easier to manage and parse queries across different database systems.
Column Schemas
We begin our definitions at the column level. The IgnoreAny type is used to bypass type checking in certain scenarios. This is necessary to avoid issues such as circular recursion checks or to terminate type checking where the compiler struggles to infer types.
The issue arises when attempting to narrow a statement like T extends SQLColumnSchema. The TypeScript compiler encounters issues because SQLColumnSchema includes columns that are generic objects of ColumnTypeDefinition<T>.It can’t determine the correct type for T, leading to a situation where no types match unless any is allowed. Scoping to something like SQLBuiltinTypes is insufficient because not all SQL types fit neatly into predefined categories, such as those with or without an autoIncrement property.
To ensure columns are valid, protections are added in other layers during schema building. Some properties are made optional with true as the only valid value to reduce edge cases. For instance, if nullable: true isn’t explicitly specified, it defaults to not-nullable, simplifying the schema-to-database materialization.
We leverage conditional types and a utility called Flattento construct ColumnTypeDefinition types. These utilities help manage properties that should only exist for specific SQL types.
The Flatten utility condenses all the intersecting option types into a single new type, making the definitions more manageable.
Utility Types
The utilities are broken down into two files, one that is more general purpose and the other for modifying objects. The Flatten and Identity types streamline complex type definitions by collapsing multiple, possibly intricate, type decorations into a more readable and manageable single type, easing both compiler and IDE processing.
The IgnoreAny type is used to bypass TypeScript checks deliberately, keeping linting minimal. The Invalid type helps detect type errors, a feature TypeScript lacks natively. Additionally, utility methods handle single objects or arrays of the same type, and ensure arrays contain at least one value.
Tables and Keys
The last of our schema types are split into tables, the overall database structure and the keys.
A key can be a single column or a collection of columns, but the order of columns in composite keys is crucial ([A, B] is not the same as [B, A]). This order must be preserved, which is managed in the SingleKey and CompositeKey classes by treating them differently—one takes a single key, the other an array of keys.
The challenge arises in maintaining this order in TypeScript. Using an array type definition like Columns extends (infer T extends StringKeys<Schema>)[] results in a union of properties, ignoring order. It’s essential to keep the columns in order because foreign key columns must match the referenced column types exactly (e.g., an INT cannot reference a JSON type). Ensuring the correct type at each array position is vital for both primary and foreign keys.
To solve this, conditionals and recursive types are used to extract and maintain the correct column types and order. This method is foundational for future developments, making it crucial to grasp its quirks and functionality through simplified examples.
Looping with Type evaluation
TheRecursiveArrayModifier type can be leveraged manipulate an array of elements (SomeType) by recursively applying a Modifier function to each element. The approach ensures type narrowing and handles arrays of varying lengths by checking if there are more than one element, then processing each element individually. If the array has more elements, it recursively modifies the current element and processes the rest.
This method is akin to using a for loop for transformations, but it faces the challenge of passing necessary context to the Modifier function consistently. While this could be turned into a utility type, the added complexity often outweighs the benefits, making the straightforward pattern preferable for readability.
A notable drawback is that each recursive step generates new types for the TypeScript compiler to track. For example, processing a type array [Foo, Bar, Baz] results in generating multiple unique types through each recursive call. This can significantly increase the number of types the compiler handles, impacting performance, especially with more complex or deeper type arrays.
Schema Building
Finally we get to Schema Building, which is a lot easier now that we have already defined the types we’ll need to leverage.
As with some of the other code, there are several utility types (not exported) which are used for manipulating the Schema types we created before. Given that we are adding keys and tables to schemas with names, the main things to note are that parameters for the addTable or addForeignKey methods both have a signature for the name. This prevents duplicates from being added so we aren’t overwriting anything. The beauty of our Invalid type in this case is that whatever string was passed isn’t likely to match up with our error message, so the compiler will flag it as an error and highlight the problem.
In the builders, class fields are marked as unknown due to constant type mutations. Maintaining typed values would require frequent object re-creation, complicating the process. The approach taken is to cast the fields each time they are returned, assuming the initial construction with type constraints ensures validity.
We focus on maintaining correct table building, specifically in the ColumnSchemaBuilder and TableSchemaBuilder classes. Define the addColumn method, to narrow down column types using the RequiredSubset utility type. This ensures that only valid properties for each ColumnType can be set, such as autoIncrement or nullable. The FinalColumnDefinition type is used to flatten column definitions to include only specified options, preventing invalid assignments. This approach eliminates optional properties that will never be used, simplifying type definitions and maintaining type safety.
Next Steps
The next article in this series will move along to use these schemas to start defining some actual queries and leverage the AST that was introduced in Part 1.
Check out the full article to go in depth with code samples:
Or go straight for the repository: